简介
日志服务(Log Service,简称 LOG)是针对日志类数据的一站式服务,无需开发就能快捷完成日志数据采集、消费、投递以及查询分析等功能,提升运维、运营效率,建立 DT 时代海量日志处理能力。
关键定义
日志(Log)
日志服务采用半结构数据模式定义一条日志。该模式中包含:
1 | 主题(Topic)、 |
日志组(LogGroup)
日志组(LogGroup)是一组日志的集合,是API/SDK写入与读取数据的基本单位,使用LogGroup主要目的是最大限度地减少读取与写入次数,提高业务效率。
一个LogGroup中的数据包含相同Meta(IP、Source等信息),这个Meta信息即为主题、来源和标签内容。
项目(Project)
项目(Project)是日志服务中的资源管理单元,用于资源隔离和控制。你可以把它看作是一个文件夹。
日志库(Logstore)
日志库(Logstore)是日志服务中日志数据的采集、存储和查询单元。你可以把它看作文件夹里面的文件。
分区(Shard)
Logstore读写日志必定保存在某一个分区(Shard)上。每个日志库(Logstore)分若干个分区,每个分区由MD5左闭右开区间组成,每个区间范围不会相互覆盖,并且所有的区间的范围是MD5整个取值范围。
分区的目的是为了提高写入效率,数据写入时会根据不同的md5值写入不同的分区。
运转流程
简单来讲,主要包括数据收集、查询分析和其他操作。其他操作有包括可视化,告警、实时消费等。其中最基本的需求是收集和查询。
数据收集
阿里提供了多种数据采集方式,支持客户端、网页、协议、SDK/API等多种日志无损采集方式,所有采集方式均基于Restful API实现。
操作系统级别:
1 | Logtail |
语言:
1 | 其中主流的语言都支持 |
数据库:
1 | MySQL Binlog |
移动端:
1 | iOS/Android SDK |
查询分析
特别注意查询与分析是两部分,格式为
1 | $Search |$Analytics |
实例:
1 | status>200 | |
建立索引:
索引分为两种:全文索引和指定字段查询。一般情况下建议开启全文索引,结构化的数据建议指定字段查询。查询时默认先按字段查询,查询不到会再按全文索引查询。如图所示content是json结构的字段,这儿注意headers.remoteip是2级的,即解析这种结构{content: {remote:{ip:'127.0.0.1'}}}
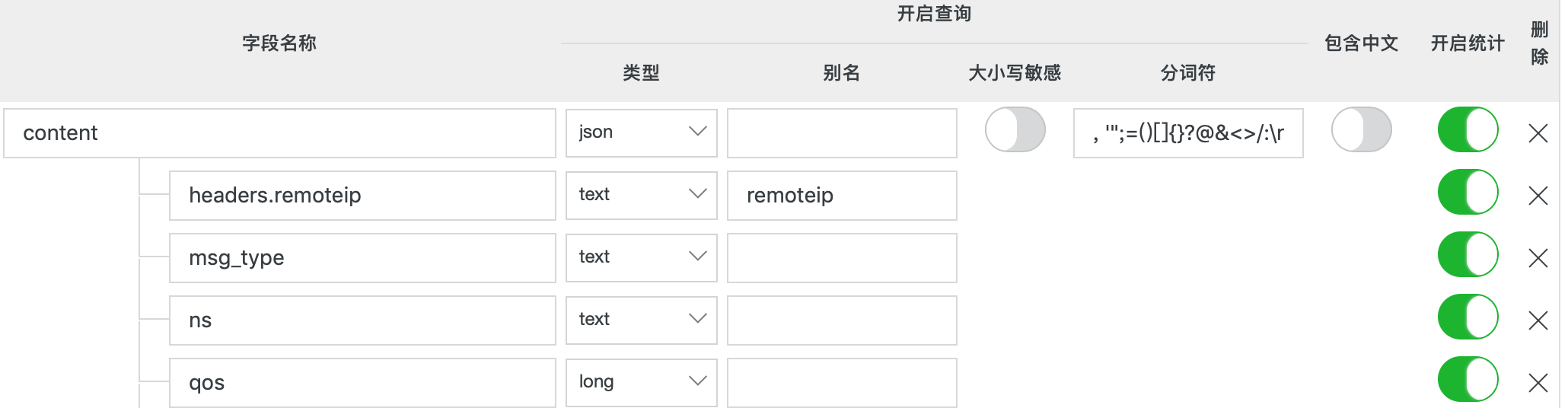
索引建立完成后,可以在快速分析看到: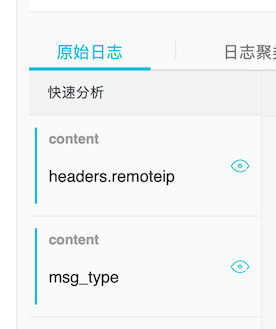
其他操作
可视化分析:
1 | 1.统计图表,可以接合分析查看一些简单的图表 |
告警:
1 | 根据需要,把日志分析和统计图表结合,设定警戒线,超过时,发出告警信息。 |
实时消费:
1 | 可实现类似kafka的功能,作为日志的消息队列 |
数据投递:
1 | 实现把数据投递到其他阿里产品,实现相关功能 |